Hi all
 Welcome to another exploration of the collaborative world through a lens called the facets of collaboration. If you are joining us for the first time, I am writing a series of posts that looks at how our perception of collaboration influences our penchant for certain collaborative tools and approaches. SharePoint, given that it is touted as a collaboration platform, inevitably results in consultants never being able to give a straight answer. This is because SharePoint is so feature-rich (and as a result caveat-rich), that there are always fifty different ways a situation can be approached. Add the fact that many clients do not necessarily know what they want and learn about their problem by examining potential solutions, we have all the hallmarks of a wicked problem in the making.
Welcome to another exploration of the collaborative world through a lens called the facets of collaboration. If you are joining us for the first time, I am writing a series of posts that looks at how our perception of collaboration influences our penchant for certain collaborative tools and approaches. SharePoint, given that it is touted as a collaboration platform, inevitably results in consultants never being able to give a straight answer. This is because SharePoint is so feature-rich (and as a result caveat-rich), that there are always fifty different ways a situation can be approached. Add the fact that many clients do not necessarily know what they want and learn about their problem by examining potential solutions, we have all the hallmarks of a wicked problem in the making.
These wicked problems, underpinning SharePoint, often results in Robot Barbie situations (cue the image to the left), which is the metaphor that I started this series with. Robot Barbie represents everything wrong about SharePoint deployments, as it is symptomatic of throwing features at a platitude, pretending to be solving a real problem and then wondering why the result doesn’t gel at all. It is a pattern of behaviour that is similar to an observation made by the very wise (and profane) Ted Dziuba who once spoke these words of wisdom.
If there’s one thing all engineers love to do, it’s create APIs. It’s so awesome because you can draw on a white board and feel like you put in a good day’s work, despite having solved no real, actual problems. Web 2.0 engineers, in addition to their intrinsic love of APIs, have a real hard-on for anything having to do with a social network. For example, developing a Facebook application lets them call their shitty little PHP program an "application" running on a "platform," like a real, live computer programmer does. Make-believe time is so much fun, even for adults.
Apart from making me giggle, Dziuba may have a point. Elsewhere on this blog I have spent time explaining that there are different types of problems that require different approaches to solving them (wicked vs. tame). My conjecture is that collaboration itself is exactly the same in this regard. People who espouse a particular type of tool or approach as the utopian solution to collaboration are taking a one size fits all approach to a multifaceted area and even worse, treating that area as a platitude. Anyone who calls themselves an Information Architect and doesn’t at least give cursory examination to the dimensions or facets of collaboration is likely to be doing their stakeholders a disservice.
All of us have certain biases, and I am no exception. For a start, I am generation X – the so-called cynical generation. Apparently we whinge and whine about everything and then blame it all on generation-Y. Thus, if cynicism is the gen-X stereotype, then I will happily accept being the poster child. I mean seriously, all of you vanity obsessed, self interested generation y’ers, if you spend a little less time preening and more time thinking, we might get some wisdom out of you (see – I am such a cynical gen-X right now).
So let’s recap the facets of collaboration. The model I came up with identifies four major facets for collaborative work: Task, Trait, Social and Transactional.
- Task: Because the outcome drives the members’ attention and participation
- Trait: Because the interest drives the members’ attention and participation
- Transactional: Because the process drives the members’ attention and participation
- Social: Because the shared insight drives the members’ attention and participation

In the last post, I used the model to examine the notion of Business Process Management versus Human Process Management and looked at some of the claims and counter claims made by proponents of each. This time let’s up the ante and talk about something curlier. We will examine the notion that social networking in the enterprise is the answer to improving collaboration within the enterprise. On first thought, it makes perfect sense, given the incredible success of Facebook, LinkedIn and Twitter. Nevertheless, there is ongoing debate about the use and value of social tools in the enterprise driven by their rise outside of organisational contexts. One particularly strongly worded quote is from Aaron Fulkerson, co-founder and CEO of MindTouch who doesn’t mince his words:
This class of software forces business users to adopt the myopic social visions imagined by the developers, which are nearly identical to their corresponding consumer web implementations. In short, social software is not solving business problems. In fact, these applications only serve to treat symptoms of the problems businesses face. They exacerbate the real problems within businesses by creating distractions and, worse, proliferate more disconnected data and application silos.
Ouch! Even within the SharePoint community there is significant variation of opinions as to the value of social. While I better protect the innocent and not name names, I have spoken with several well known SharePointers who think social is a giant waste of time, versus those who see real value in it. Irrespective of your opinion, you cannot ignore the fact that social is a significant game changer with effects still being felt. While web 2.0 has dropped off the Gartner hype cycle, its effect on particular sectors has been far reaching. Now it seems that all sectors have a 2.0 on the end of their name. For example:
- Enterprise 2.0
- Education 2.0
- Legal 2.0
- Government 2.0
Clearly, if things were just a flash in the pan, why are governments around the world trying to revitalise their public sector by utilising these tools?
Look at Microsoft as another example. They have, I think smartly, recognised industry trends and reacted to them via the introduction of a number of new SharePoint features, such as tagging/folksonomy via managed metadata, ratings columns, enhanced wiki capabilities and a significant investment in the capabilities of my-sites. Their clients now have the option to leverage these features should they choose to do so.
So just as there are naysayers, there are the pundits. Many people cite the reasoning that these features are necessary to attract and retain the next generation of workers, who have grown up with these tools in their personal lives. Whether this claim is valid is debatable, but I have to say, I really like the Enterprise 2.0 slide deck below by Scott Gavin for a number of reasons. I think it encapsulates the 2.0 vision, underpinned by social/cloud technologies very nicely. I sometimes ask people to discuss this slide deck in my IA classes and discussion is equally polarising as social networking in the enterprise itself. Some people think it represents the vision for the future, and others think it is hopelessly idealistic and doesn’t reflect cold, hard reality. Take a look for yourself below…
And the survey says…
Using the facets quadrants, we can start to see patterns for success of these tools for the enterprise and whether Aaron Fulkerson’s argument has merit or whether Scott Gavin is on the right track. An interesting use of the facet diagram is to plot where various tools and technologies are located. in my classes, I ask people to plot where Facebook belongs on facets diagram. Guess where it is usually drawn?

While some people will draw Facebook at various levels on the vertical axis, everyone pretty much describes Facebook (and LinkedIn) as trait based, while being highly dominant on the social quadrant. As discussed in the last article, if I ask people to plot a crowdsourced tool like Wikipedia, the dominant characteristic is always trait/social. In other words, people maintain and update Wikipedia articles because of their interest in the topic area, not because it helps them get something done.

Clearly, big social networking technologies are successful in the "trait based social” quadrant. In other words, we tend to use Facebook more for common interest collaboration than to solve a task based collaborative issue (such as deliver a project). Another interesting thing about a lot of social networking technologies is that for many, our work-based collaborative life tends to be more task based, compared to our non-work which is more trait based. In other words, for a lot of us, our work life revolves around working with a group of people for a common outcome and if it was not for that common outcome, we wouldn’t necessarily have much in common (I risk falling victim to my own generalisation here – so I will come back to this later in the section titled “Why User Buy-In Is Hard”).
When you look at where Facebook sits in the quadrant, it begs the question of how well this type of tool (or the building blocks it is based on) would work in an organisation that is project (task) based and highly transactional. To that end, consider a project management information system, such as the basic one that Dux espouses in his book or the more complex one that Microsoft sell to organisations. Where do you think it belongs on the quadrant?
When I ask people to plot their project management information system, I typically get this response:

I speculate that the further away two tools lie on the spectrum, the more likely we are to have a robot-barbie solution if you blindly mix features that work well in each individual quadrant. The wiki argument I made in part 3 seems to support this contention. If you recall, in part 3 of this series, I mentioned that I ask every attendee of my classes if they had ever seen a successful project management wiki. Irrespective of the location of the class, the answer was pretty much “no”. I noted that where I had seen successful wikis tended to be where the users of the wiki were linked by strong traits.
Looking Deeper
While that is interesting, I think the facets diagram tells you more than it intends. Obviously, it is clear that these project management systems such as MS Project Server are oriented toward task/transactional (“getting things done”) aspect of project delivery (ie, time, cost, scope, budget and the like). While some people might point to this and say “there you go – I told you all that social crap was a waste of time – bloody gen-Y and their social networking hubris”, I feel this is naive. If task based transactional tools are sufficient, then why do so many projects fail?
I have stated many times on this blog that shared commitment to a course of action requires shared understanding of the problem at hand. The act of aligning a team to project goals and developing this shared understanding is the realm of the task/social quadrant (the top left), where insights and outcomes come together. When I ask people to name tools that live in this space, few can name anything. Obviously, most project management systems are devoid here. Worst still, we subsequently delude ourselves to thinking that shared understanding can come from a few platitudinal paragraphs labelled as a “problem statement”.
Social networking pundits implicitly recognise this issue (and frequently butt heads against command and control type project managers as a result). But i feel they make the mistake in applying a one size fits all approach to collaboration and apply trait based tools as a panacea when they are not wholly appropriate. The social tools seem to fit exceptionally well into the top right quadrant, but not in the top left.
In fact the only tools that spring to mind that belong in the top left category are the sensemaking tools that my company practice, such as Dialogue Mapping.
Where’s the proof, Paul?
So I guess I am arguing that using social tools because they are the “choice of the new generation” ignores a few home truths about the nature of these tools versus the nature of organisational life. Just because Microsoft provide the tools for you, tells you that they are hedging their bets rather than having any more insight than you or me. So to test all of this, let’s use the facets model in a different way to back up some of my observations and suggestions in this post. Guess what happens when I ask people to plot SharePoint itself on the facets map?
When I asked SharePoint practitioners to do this, they initially drew SharePoint 2007 as a circle over the entire model. Once they did so, they would very often adjust the drawing to emphasise transactional over social collaboration as shown below.

When practitioners were asked to draw SharePoint 2010, they usually indicated a higher representation in in the two social quadrants, but favoured the trait based social over task based social as shown below.

What was interesting about this experiment is that very few people drew SharePoint over the entire facets of collaboration. Social collaboration with SharePoint it seems, only stretches so far. This leads me onto more conjecture, and now we get to the bit in the post where we name a giant SharePoint elephant in the room.
Structured tools for social collaboration?
Many collaborative tools purport themselves as operating in the social space. SharePoint 2010 clearly does so, principally due to the Managed Metadata service, pimped MySites with tagging/rating capabilities. But SharePoint’s core heritage is database/metadata driven, document based collaboration. If we go back to our definition of social collaboration as dynamic, unstructured, with sharing of perspectives and insight through pattern sensing, then social collaboration is clearly not a predefined interaction.
Yet, database driven tools like SharePoint, and its building blocks like site columns and content types require considerable up-front planning to install and govern. Many, many inputs need to be well defined and furthermore, unless you have learnt through living the pain of things like content type definitions in declarative CAML, SharePoint buildings blocks are difficult to maintain/change over time. SharePoint suffers from a problem of reduced resiliency over time in that the more you customise it to suit your ends, the less flexible it gets. In the case of social collaboration the problem is worse because we are trying design for outputs where the inputs are not controlled. Trying to turn something that is inherently organic and emergent to something that has an X and Y on it may be misfocused and destined to fail in many circumstances. The realm of well-defined inputs is the realm of transactional collaboration, where workflow and business process management thrive and change is much more controlled before SharePoint ever gets a look in.
SharePoint excels at transactional scenarios as this is its heritage – after all, the majority of its feature set is oriented to transactional collaboration. The fact that people are prepared to draw SharePoint as dominating across across the transactional half of the facets diagram illustrates this.
But this raises interesting, if not slightly heretical question. If we need to use information architects to get a collaborative tool deployed for social collaboration (to get those inputs defined), then are we pushing the solution into the transactional side of the fence? Recall that in part 3 of this series, I looked at document collaboration and noted that when asked to draw team based document collaboration, people typically drew it operating in the social half of the matrix (pasted below for reference). I also noted in part 3 that for team based collaboration, rules and process are much less rigid or formalised with regards to document use and structure. I then referred to a recent NothingbutSharePoint article where a large organisation’s attempts to introduce the usage of content types largely failed. Like the seeming lack of success of wiki’s for task based collaboration, maybe content types simply are not the ideal construct as you move up the Y axis from transactional to social?
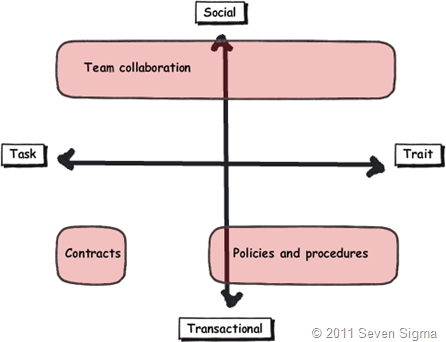
Now do not assume that I am anti metadata/content types here as this is not the case at all. Content types rock when it comes to search and surfacing of related information across a site collection (and beyond if you use search web parts). What I am calling out is the fact that if the SharePoint constructs that we have at our disposal were the panacea for social collaboration, where are the best practices that tell us how to leverage them for success? Perhaps the nature of the collaboration taking place plays a part in the lack of take-up reported in the aforementioned article? Those who advocate highly structured metadata as the only true solution may in fact be pushing a transactional paradigm onto a collaborative model that is ill-suited to it?
The knowledge worker paradox – one of the reasons why user buy-in is hard
Finally for now I’d like to cover one more aspect to this issue. Last year, one of my students looked at the facets and said “Now I know why my users aren’t seeing the value that I see in SharePoint”. When I asked him why, he explained:
“Many of my users are transactional and governed by process – that’s their KPI. Here I am as a knowledge worker, seeing all of these great collaborative features, but I am not judged by a process or transaction. I don’t live in that world. I forget that someone whose performance is judged by process consistency is not going to get all excited by a wiki or tagging or a blog.”
I call this the knowledge worker paradox and it is reminiscent of what I said in part 4 where we looked at BPM vs. HPM. Each role on an organisation is multifaceted. For many roles, there is varying degrees of transactional work taking place. Accordingly some people are very much process driven just as much as they are social driven. Gross generalisations that make statements that “80% of people are knowledge workers or perform knowledge work” do not help matters. In fact they serve to feed the one size fits all mentality that has proven to be detrimental to projects when people fail to recognise that some projects have wicked aspects.
SharePoint people are almost always knowledge workers. Thus if you, as a knowledge worker who is rarely governed by transactional process, think that you have the vision to prescribe a SharePoint driven meta-utopia to meet transactional needs without having lived that world, then if your results are not what you hoped for then to me its hardly surprising. My student in this case realised that he had been approaching his user base the wrong way. Like Jane in part 1, he did not take into account the dominant facets of collaboration for the roles that he was trying to sell SharePoint into.
When you think about it, the whole argument around records management versus collaborative document management is in effect, an argument between a transactional oriented approach, versus a social oriented one. It is the same pattern as BPM vs. HPM. In records management, the paradigm is that management of the record is more important than the content of the record. Furthermore, that record shouldn’t change. Yet with team based document collaboration, without content there is no document as such and furthermore, the document will change frequently and require less strict controls to grease the gears of collaboration.
Both records oriented people and social pundits commonly make the same mistake of my student, where they force their dominant paradigm on everyone else.
Conclusion
Food for thought, eh?
This is probably my last facets of collaboration post for a while. It is one of these series of articles that I feel has value, but I know it won’t be read by too many 🙂 Nevertheless, I do hope that anyone who has gotten this far through has gotten some value from this examination and sees value in the model to help users make more informed Information Architecture decisions for SharePoint and beyond. I certainly use it now in most engagements and hope that it can be improved upon as a tool, or somehow incorporated into some of the SharePoint standards or maturity model stuff that is out there.
Remember the most important thing of all though. Despite all I have said, it is still definitely all generation y’s fault!
Thanks for reading
Paul Culmsee
www.sevensigma.com.au




















