At the time of writing, a common request for PowerApps is to be able to able to upload photos to SharePoint. It makes perfect sense, especially now that its really easy to make a PowerApp that is bound to a SharePoint list. Sadly, although Microsoft have long acknowledged the need in the PowerUsers forum, a solution has not been forthcoming.
<update>I now use a Flow-based method for photos that I documented in this video. I only use this method in complex scenarios</update>
I have looked at the various workarounds, such as using the OneDrive connector or a custom web API, but these for me were fiddly. Thanks to ideas from John Liu, I’ve come up with a method that is more flexible and less fiddly to implement, provided you are okay with a bit of PowerShell, and (hopefully) with PnP PowerShell. One advantage to the method is that it handles an entire gallery of photos in a single transaction, rather than just a single photo at a time.
Now in the old days I would have meticulously planned out a multi-part series of posts related to a topic like this, because I have to pull together quite a lot of conceptual threads into a single solution. But since the pace of change in the world of Office365 is so rapid, my solution may be out of date by the time I publish it. So instead I offer a single summary post of my solution and leave the rest to you to figure out. Sorry followers, its just too hard to do epic multi-part articles these days – times have changed.
What you need
- An understanding of JSON and basic idea of web services
- An azure subscription
- Access to Azure functions
- The PnP Powershell cmdlets
- A Swagger file (don’t worry if this makes no sense now)
- To be signed up to PowerApps
How we are going to solve this…
In a nutshell, we will create an Azure function, using PowerShell to receive photos from PowerApps and uploads them to a SharePoint library. Here is my conceptual diagram that I spent hours and hours drawing…

To do this we will need to do a few things.
- Customise PowerApps to store photo data in the way we need
- Create and configure our Azure function
- Write and test the PowerShell code to upload to SharePoint
- Create a Swagger file so that PowerApps can talk to our Azure function
- Create a custom PowerApps connection/datasource use the Azure function
- Test successfully and bask in the glory of your awesomeness
Step 1: Customise PowerApps to store photo data in the way we need
Let’s set up a basic proof of concept PowerApp. We will add a camera control to take photos, a picture gallery to view the photos and a button to submit the photos to SharePoint. I’ll use the PowerApps desktop client rather than the web page for this task and create a blank app using the Phone Layout.

From the Insert menu, add a Camera control from the Media dropdown to add it to the screen. Leave it up near the top…

From the Insert Menu, add a Gallery control. For my demo I will use the vertical gallery. Move it down below the camera control so it looks like the second image below.


From the Insert Menu, add two buttons below the gallery. Set the text property on one to “Submit” and the other to “Clear”. I realise the resulting layout will not win any design awards but just go with it. Use the picture below to guide you.


Now let’s wire up some magic. Firstly, we will set it up so clicking on the camera control will take a photo, and save it to PowerApps storage. To do this we will use the Collect function. Assuming your Camera control is called “Camera1”, select it , and set the OnSelect property to:
Collect(PictureList,Camera1.Photo)

Now when a photo is taken, it is added to an in-memory PowerApps data-source called PictureList. To see this in action, preview the PowerApp and click the camera control a couple of times. Exit the preview and choose “Collections” from the left hand menu. You will now see the PictureList collection with the photos you just took, stored in a field called Url. The reason it is called URL and not “Photo” will become clear later).

Now let’s wire up the clear button to clear out this collection. Choose the button labelled “Clear” and set its OnSelect property to:
Clear(PictureList)

If you preview the app and click this button, you will see that the collection is now empty of pictures.
The next step is to wire up the Gallery to the PictureList collection so that you can see the photos being taken. To do this, select the gallery control and set the Items property to PictureList as shown below. Preview this and you should be able to take a set of photos, see them added to the gallery and be able to clear the gallery via the button.


Now we get to a task that will not necessarily make sense until later. We need to massage the PictureList collection to get it into the right format to send to SharePoint. For example, each photo needs a filename, and in a real-world scenario, we would likely further customise the gallery to capture additional information about each photo. For this post I will not do this, but I want to show you how you can manipulate data structures in PowerApps. To do this, we are going to now wire up some logic to the “Submit” button. First I will give you the code before I explain it.
Clear(SubmitData);
ForAll(PictureList,Collect(SubmitData, { filename: "a file.jpg", filebody: Url }))

In PowerApps, it is common to add multiple statements to controls, separated by a semicolon. Thus, the first line above initialises a new Collection I have called “SubmitData”. If this collection already had data in it, the Clear function will wipe it out. The second line uses two functions, ForAll and the previously introduced Collect. ForAll([collection],[formula]) will iterate through [collection] and perform tasks specified in [formula]. In our case we are adding records to the SubmitData collection. Each record consists of two fields and is in JSON format – hence the curly braces. The first field is called filename and the second is called filebody. In my example the filename is a fixed string, but filebody grabs the Url field from the current item in PictureList.
To see the effect, run the app, click submit and then re-examine the collections. Now you will see two collections listed – the original one that captures the photos from the camera (PictureList), and the one called SubmitData that now has a field for filename and a field called filebody with the photo. I realise that setting a static filename called “a file.jpg” is not particularly useful to anybody, and I will address this a little later, the point is we now have the data in the format we need.

By the way, behind the scenes, PowerApps stores the photo in the Data URI scheme. This is essentially a Base64 encoded version of the image with a descriptor at the start that is included in HTML. When you think about it, this makes sense in some situations because it reduces the number of HTTP round trips between browser and server. For example here is a small image encoded and embedded direct in HTML using the technique.
<img src="data:image/png;base64,iVBORw0KGgoAAA
ANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4
//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU
5ErkJggg==" alt="Red dot" />
The implication of this format is when PowerApps talks to our Azure function, it will send this sort of JSON…
[ { "filename": "boo.jpg",
"filebody": "data:image/jpeg;base64,/9j/4AAQSkZJR [ snip heaps of Base64 ] T//Z" },
{ "filename": "boo3.jpg",
"filebody": "data:image/jpeg;base64,/9j/TwBAQMEBA [ snip heaps of Base64 ] m22I" } ]
In the next section we will set up an Azure Function and write the code to handle the above format, so save the app in its current state and give it a nice name. We are done with PowerApps for now…
2. Create and Configure Azure Function
Next we are going to create an Azure function. This is the bit that is likely new knowledge for many readers. You can read all about them on their Azure page, but my quick explanation is that they allow you to take a script or small piece of code and turn it into a fully fledged webservice. As you will soon see, this is very useful indeed (as well as very cost effective).
Now like many IT Pros, I am a PowerShell hacker and I have been using the PowerShell PnP libraries for all sorts of administrative purposes for quite some time. In fact if you are administering an Office365 tenant and you are not using PnP, then I can honestly say you are missing out on some amazing time-saving toolsvand you owe it to yourself to skill-up in this area. Of course, I realise that many readers will not be familiar with PowerShell, let alone PnP, and I expect some readers have not done much coding at all. Luckily the code we are going to use is just a few lines and I think I can sufficiently explain it.
But we are getting ahead of ourselves, let’s create the Azure function and then revisit PowerShell. Assuming you have an Azure subscription, visit functions.azure.com and log in. If not, sign up for the free account and then create a function app to host the function. I called mine MyFunctionsDemo but yours will have to be something different. This will take minute or two to complete and you will be redirected to the Azure functions portal.


Once the web application to host your functions is created, Click the + next to the Functions button to create a new function. PowerShell is still in preview, so you have to click the option to create a custom function. On the next screen, in the Language dropdown, choose PowerShell.


Our function is going to be triggered from PowerApps when a user clicks the submit button. PowerApps will make a HTTP request so this is a HttpTrigger scenario. Click the HttpTrigger-PowerShell template, give it a name (I called mine PhotoSendSP) and click the Create button. If all goes to plan you will be presented with a screen with some basic PowerShell code… essentially a “Hello World” web service.


Let’s test this newly minted Azure function before we customise it. If you look to the right of the screen above, you will see a “Test” vertical label. Click it and you will be presented with a screen that allows you to craft some data to send to your shiny new function. You can see that the test is going to be a HTTP POST by default. As you can see below, there is a basic JSON entry with a single name/value pair “name”: “Azure”. Change the Azure string to something else and then click the Run button. The result will be displayed below the JSON as shown below.


Now let’s take a quick look at the PowerShell code provided to you by default. Only lines 2, 3 and 11 matter for our purposes. What lines 2 and 3 show is that all of the details that are posted to this webservice are stored in a variable called $req. Line 2 converts this to JSON format and stores that in a variable called $requestbody. Line 3 then asks $requestbody for the value of “name”, which is you look in the screenshots above are what you set in the test. Line 11 then outputs this line to a variable called $res, which is the response back to the caller of this webservice. In this case you can see it returns “Hello “ with $name appended to it.

Now that we have seen the PowerShell code, let’s now update it with code to receive data from PowerApps and send it to SharePoint.
3. Write and test the PowerShell code that uploads to SharePoint
If you recall with PowerApps, the data we are sending to SharePoint is one or more photos. The data will look like this…
[ { "filename": "boo.jpg",
"filebody": "data:image/jpeg;base64,/9j/4AAQSkZJR [ snip heaps of Base64 ] T//Z" },
{ "filename": "boo3.jpg",
"filebody": "data:image/jpeg;base64,/9j/TwBDAQMEBAUEBQ m22I" } ]
In addition, for the purposes of keeping things simple, I am going to hard code various things like the document library to save the files to and not worry about exception handling. Below is my sample code with annotations at the end…
1. Import-Module "D:\home\site\wwwroot\modules\SharePointPnPPowerShellOnline\2.15.1705.0\SharePointPnPPowerShellOnline.psd1" -Global
2. $requestBody = Get-Content $req -Raw | ConvertFrom-Json
3. $username = "paul@tenant.onmicrosoft.com"
4. $password = $env:PW;
5. $siteUrl = "https://tenant.sharepoint.com"
6. $secpasswd = ConvertTo-SecureString $password -AsPlainText -Force
7. $creds = New-Object System.Management.Automation.PSCredential ($username, $secpasswd)
8. Connect-PnPOnline -url $siteUrl -Credentials $creds
9. $ctx = get-pnpcontext
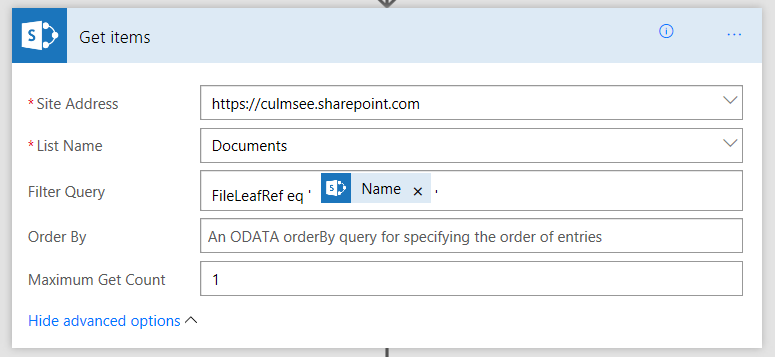
10. $doclib = $ctx.Web.Lists.GetByTitle("Documents")
11. ForEach ($item in $requestbody)
12. {
13. $filename = $item.filename
14. $rawfiledata = $item.filebody
15. $rawfiledata = $rawfiledata -replace 'data:image/jpeg;base64,', ''
16. $bytes = [System.Convert]::FromBase64String($rawfiledata)
17. # uses comma notation related to .net reflection http://piers7.blogspot.com.au/2010/03/3-powershell-array-gotchas.html
18. $memoryStream = New-Object System.IO.MemoryStream (,$bytes)
19. $FileCreationInfo = New-Object Microsoft.SharePoint.Client.FileCreationInformation
20. $FileCreationInfo.Overwrite = $true
21. $FileCreationInfo.ContentStream = $memoryStream
22. $FileCreationInfo.URL = $filename
23. $Upload = $doclib.RootFolder.Files.Add($FileCreationInfo)
24. $ctx.Load($Upload)
25. $ctx.ExecuteQuery()
26. }
- Line 1 loads the PnP PowerShell module. Without this, commands like Connect-PnPOnline and Get-PnPContext will not work. I’ll show how this is done after explaining the rest of the code.
- Lines 3-7 are all about connecting to my SharePoint online tenant. Line 4 contains a variable called $env:PW. The idea here is to avoid passwords being stored in the code in clear text. The password is instead is pulled from an environment variable that I will show later.
- Lines 7-9 connect to a site collection and then connect to the default document library within it.
- Line 10 looks at the data sent from PowerApps and loops around to process for each image/filename pair.
- Lines 13-18 grabs the file name and file data. It converts the file data into a memorystream, which is a way to represent a file in memory.
- Line 19-25 then uploads the in-memory image to the document library in SharePoint, based on the filename provided. (Note: any PnP gurus wondering why I did not use Add-PnPFile, it was because this cmdlet did not properly handle the memorystream and the images were not proper binary and always broken.)
So now that we have seen the code, lets sort out some final configuration to make this all work. A lot of the next section I learnt from John Liu and watching the excellent Office Patterns and Practices Special Interest Group webinar he recently did with my all-time SharePoint hero, Vesa Juvonen.
Installing PnP PowerShell Components
First up, none of this will work without the PnP PowerShell module deployed to the Azure Function App. The easiest way to do this is to install the PnP PowerShell cmdlets locally and then copy the entire installation up to the Azure function environment. John Liu explains this in the aforementioned webinar but in summary, the easiest way to do this is to use the Kudu tool that comes bolted onto Azure functions. You can find it by clicking the Azure function name (“MyFunctionDemo” in my case) and choosing the “Platform Features” menu. From here you will find Kudu hiding under the Development Tools section. When the Kudu tab loads, click the Debug console menu and create a CMD or PowerShell console (it doesn’t matter which)



We are going to use this console to copy up the PnP PowerShell components. You can ignore the debug console and focus on the top half of the screen. This is showing you the top level folder structure for the Azure function application. Click on site and then wwwroot folders. This is the folder where all of your functions are stored (you will see a folder matching the name of the module we made in step 2). What we will do is install the PnP modules at this level, so it can be used for other functions that you are sure to develop  .
.


So click the + icon to create a folder here and call it Modules. From here, drag and drop the PnP PowerShell install location to this folder. In my case C:\Program Files\WindowsPowerShell\Modules\SharePointPnPPowerShellOnline\2.15.1705.0. I copied the SharePointPnPPowerShellOnline\2.15.1705.0 folder and all of its content here as I want to be able to maintain multiple versions of PnP as I develop functions over time.


Now that you have done this, the first line of the PowerShell script will make sense. Make sure you update the version number in the Import-Mobile command to the version of PnP you uploaded.
Import-Module "D:\home\site\wwwroot\modules\SharePointPnPPowerShellOnline\2.15.1705.0\SharePointPnPPowerShellOnline.psd1"
Handling passwords
The next thing we have to do is address the issue of passwords. This is where the $env:PW comes in on line 4 of my code. You see, when you set up Azure functions application, you can create your own settings that can drive the behaviour of your functions. In this case, we have made an environment variable called PW which we will store the password to access this site collection. This hides clear text passwords from code, but unfortunately it is a security by obscurity scenario, since anyone with access to the Azure function can review the environment variable and retrieve it. If I get time, I will revisit this via App Only Authentication and see how I go. I suspect though that this problem will get “properly” solved when Azure functions support using the Azure Key Vault.
In any event, you will find this under the Applications Settings link in the Platform Features tab. Scroll down until you find the “App Settings” section and add your password in as shown in the second image below.


Testing it out…
Right! At this point, we have all the plumbing done. Let’s test to see how it goes. First we need to create a JSON file in the required format that I explained earlier (the array of filename and filebody pairs). I crafted these by hand in notepad as they are pretty simple. To remind you the format was:
[ { "filename": "boo.jpg",
"filebody": "data:image/jpeg;base64,/9j/4AAQSkZJR [ snip heaps of Base64 ] T//Z" },
{ "filename": "boo3.jpg",
"filebody": "data:image/jpeg;base64,/9j/TwBDAQMEB [ snip heaps of Base64 ] m22I" } ]
To generate the filebody elements, I used the covers of my two books (they are awesome – buy them!) and called them HG2BP and HG2M respectively. To create the base 64 encoded images in the Data URI scheme, I went to https://www.base64-image.de and generated the encoded versions. If you are lazy and want to use a pre-prepared file, just download the one I used for testing.



To test it, all we need to do is click the right hand Test link and paste the JSON into it. Click the Run button and hope for the best! As you can see in my example below, the web service returned a 200 status which means hunky dory, and the logs showed the script executing successfully.

Checking my document library and they are there… wohoo!!

So basically we have a lot of the bits in place. We have proven that our Azure function can take a JSON file with encoded images, process that file and then save it to a SharePoint document library. You might be thinking that all we need to do now is to wire up PowerApps to this function? Yeah, so did I too, but little did I realise the pain I was about to endure…
4. Create a Swagger file so that PowerApps can talk to our Azure function
Now we come to the most painful part of this whole saga. We need to describe our Azure function using a standard called Swagger (or OpenAPI). This provides important metadata so that PowerApps can make it easy for users to consume. This will make sense soon enough, but first we have to create it, which is a royal pain in the ass. I found the online documentation for swagger to be lacking and it took me a while to understand enough of the format to get it working.
So first up to make things simpler, let’s reduce some of the complexity. Our Azure function is a simple HTTP post. We have not defined any other type of requests, so lets make this formal as it will generate a much less ugly Swagger definition. Expand your function and choose the “Integrate” option. On the next screen, under Triggers, you will find a drop down with a label “Allowed HTTP methods”. Change the default value to “Selected methods” and then untick all HTTP methods except for POST. Click Save.



Now click back to your function app, and choose “API Definition” from the top menu. This will take you to the screen where you create/define your Swagger file.

On the initial screen, set your API definition source to function if asked, and you should see a screen that looks somewhat like this…

Click the Generate API definition template button as suggested by the comment in the code box in the middle. This will generate a swagger file and on the right side of the screen, the file has will be used to generate a summary of your API. You can see the Url of your azure app, some information about an API key (which we will deal with later) and below that, the PhotoSendSP function exposed as a webservice (/api/PhotoSendSP).

Now at this point you are probably thinking “okay so its unfamiliar, but this is pretty easy”, and you would be right. Where things got nightmarish for me was working out how to understand and customise the swagger file as the template is currently incomplete. All it has done is defined our function (note the paths section in the above screenshot – can you see all those empty square brackets? that’s what you need to now fill in).
For the sake of brevity, I am not going to describe the ins and outs of this format (and I don’t fully know it yet anyway!). What I can tell you is that getting this right is a painful and time-consuming combination of trial and error, reading the swagger spec and testing in PowerApps. Let’s hope my hints here save you some frustration.
The first step is we need to create a definition for the format of data that our Azure function accepts as input. If you look closely above, you will see a section called definitions. Paste the following into the section so it looks like the screenshot below. Note: If you see any symbol apart from a benign warning message next to the “Photos:” line, then you do not have it right!.
definitions:
Photos:
type: object
required:
- filename
- filebody
properties:
filename:
type: string
example: image.jpg
filebody:
type: string

So what we have defined here is an object called Photos which consists of two required properties, filename and filebody. Both are assumed to be string format, and filename also has an example to illustrate what is expected. Depending on how this swagger file is consumed by another application that supports swagger, one can imagine that example showing up on online help or intellisense when our function is being called.
Now lets make use of this definition. Paste this into the parameters and description sections. Note the “schema:” section. Here we have told the swagger file that our function is expecting an array of objects based on the Photos definition that we created earlier.
parameters:
- name: photocollection
in: body
description: “The encoded files”
required: true
schema:
type: array
items:
$ref: '#/definitions/Photos'
description: "A collection of photos and filenames"

Finally, let’s finish off by defining that our Azure function consumes and produces its data in JSON format. Although our sample code is not producing anything back to PowerApps, you can imagine situations where we might do something like send back a JSON array of all of the SharePoint URL’s of each photo.
produces:
- application/json
consumes:
- application/json

Okay, so we are all set. Now to be clear, there is a lot more to Swagger, especially if you wanted to call our function from flow, but for now this is enough. Click the Save button, and then click the button “Export to PowerApps + Flow”. You will be presented with a new panel that explains the process we are about to do. Feel free to read it, but the key step is to download the swagger file we just created.

Okay, so if you have made it this far, you have a swagger JSON file and you are in the home stretch. Let’s now head back to PowerApps!
5. Create a custom PowerApps connection/datasource to use the Azure function
Back in PowerApps, we need to make a new custom connection to our Azure function. Click the Connections menu item and you will be redirected to web,powerapps.com. Click “Manage Custom Connections” and then click “Create a custom connector”. This will take you to a wizard.



The first step is to upload the swagger file you created in step 4 and before you do anything else, rename your connector to something short and sweet, as this will make it easier when displayed in the PowerApps list of connections.

Scroll to the bottom the of page and click the “Continue” button. Now you are presented with some security options about your connector. For context, the default settings for the PowerShell azure function template we chose in step 2 was to use an API key, so you can leave all of the defaults here, although I like to add the more meaningful “API Key” (this will make sense soon). Click Continue…

PowerApps has now processed the swagger file and found the PhotoSendSP POST action we defined. It has also pulled some of the data from the swagger file to prepopulate some fields. Note this screen has some UI problems – you need to hover your cursor over the forms in the middle of the screen to see the scrollbar, so there is more to edit than what you initially see…

For now, do not enter anything into the summary field and scroll down to look at some of the other settings. The Visibility setting does not really matter for PowerApps, but remember that other online services can call our function. This visibility stuff relates more to Microsoft Flow, so you can ignore it for now. Scroll further down and you will see how our swagger schema has been processed by PowerApps. You can explore this but I suggest leaving it well alone. Below I have used all my MSPaint skills to make a montage to show how this relates to your Swagger file…

Finally, click Create Connector to wire it up. If all has gone to plan, you will see something resembling the following in the list of custom connectors in PowerApps. If you get this far, congratulations! You are almost there!

6. Test successfully and bask in the glory of your awesomeness
Now that you have a custom connection, let’s try it out. Open your PowerApp that you created in step 1. From the Content menu, click Data sources, click Add Datasource and then click New Connection. Scroll through the list of connections until you find the one you created in step 5. Click on it and you will be prompted for an API key (now you see why I added that friendly label during step 5).



Where to find this key? Well, it turns out that it was automagically generated for you when you first created your function! Go back to Azure functions portal and find your function. From the function sub menus, click Manage and you will be presented with a “Functions Keys” section with a default key listed. Copy this to the clipboard, and paste it back into the PowerApps API Key text box and click the Create button. Your datasource that connects to your Azure function is now configured in PowerApps!! (yay!).



Now way back in step 1 (gosh it seems like such a long time ago), we created a button labelled Submit, with the following formula.
Clear(SubmitData);
ForAll(PictureList,Collect(SubmitData, { filename: "a file.jpg", filebody: Url }))
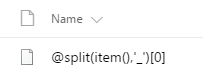
The problem we are going to have is that all files submitted to the webservice will be called “a file.jpg” as I hardcoded the filename parameter for simplicity. Now if I fully developed this app, I would add a textbox to the gallery so that each photo has to be named prior to being able to submit to SharePoint. I am not going to do that here as this post is already too long, so instead I will use a trick I saw here to create a random two letter filename. I know it is not truly unique, but for our demo will suffice.
Here is the formula in all its ugliness.
Concatenate(Text( Now(), DateTimeFormat.LongDate ),Mid("0123456789ABCDEFGHIJKLMNOPQRTSTIUVWXYZ", 1 + RoundDown(Rand() * 36, 0), 1),Mid("0123456789ABCDEFGHIJKLMNOPQRTSTIUVWXYZ", 1 + RoundDown(Rand() * 36, 0), 1),".jpg"), filebody: Url } ) )
Yeah I know… let me break it down for you…
- Text( Now(), DateTimeFormat.LongDate ) produces a string containing todays date
- Mid(“0123456789ABCDEFGHIJKLMNOPQRTSTIUVWXYZ”, 1 + RoundDown(Rand() * 36, 0), 1) – selects a random letter/number from the string
- Concatenate takes the above date, random letters and adds “.jpg” to it.
PowerApps does allow for line breaks in code, so it looks less ugly…

Let’s quickly test this before the final step of sending it off to SharePoint. Preview the app, take some photos and then examine the collections. As you can see, the SubmitData collection now has unique filenames assigned (By the way, yes I took these in a car and no, I was not driving at the time! 🙂

We are now ready for the final step. We need to call the Azure function!
Go back to your submit button and add the following code to the end of the existing code, taking into account the name you gave to your connection/datasource. You should find that PowerApps uses intellisense to help you add the line because it has a lot of metadata from the swagger file.
'myfunctionsdemo.azurewebsites.net'.apiPhotoSendSPpost(SubmitData)

Important! Before we go any further, I strongly suggest you use the PowerApps web based authoring environment and not the desktop application. I have seen a problem where the desktop application does not encode images using the Data URI format, whereas the web based tool (and PowerApps clients on android and IOS) work fine.
So log into PowerApps on the web, open your app, preview it and cross your fingers! (If you want to be clever, go back to your function in Azure and keep and eye on the logs

As the above screen shows, things are looking good. Let’s check the SharePoint document library that the script uploads to… YEAH BABY!! We have our photos!!!

Conclusion
Now you finally get to bask in your awesomeness. If you survived all this plumbing and have gotten this working then congratulations! you are well on your way to becoming a PowerApps, PowerShell, PnP (and flow) guru. This means you can now enhance your apps in all sorts of ways. For the non-developers who got this far, you can truly call yourself a citizen developer and design all sorts of innovative solutions via these techniques.
Even though a lot of this stuff is fiddly (especially that god-awful swagger crap), once you have gone through it a couple of times, and understand the intent of the components we have used, this is actually quite an easy solution to put together. I also found the Azure function side of things in particular, really easy to debug and see what was going on.
In terms of where we could take this, there are several avenues that I can immediately think of, but the possibilities are endless.
- We could update the PowerShell code so it takes the destination document library as a parameter. We would need to update a new Swagger definition and then update our datasource in PowerApps, but that is not too hard a task once you have the basics working.
- Using the same method, we could design a much more sophisticated form and capture lots of useful metadata with the pictures, and get them into SharePoint as metadata on the picture.
- We could add in a lot more error handling into the script and return much better detail to PowerApps, such as detailed failure information.
- Similarly, we could return detailed information to PowerApps to make the app richer. For example, we could generate unique filenames in our PowerShell function rather than PowerApps and return those names (and the URL to the image) in the reply to the HTTP Post, which would enable PowerApps to display images inline.
- We could also take advantage of recent PowerApps enhancements and use local caching. I.e, when an internet connection is available, call the API, but if not, save to local storage and call the API once a connection is available.
- We could not only upload images, but update lists and any other combination of SharePoint functions supported by PnP.
I hope that this post has helped you to better understand how these components hang together and I look forward to your feedback and how you have adopted/adapted and enhanced the ideas presented here.
Thanks for reading
Paul Culmsee
www.hereticsguidebooks.com





![image_thumb[6]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb6_thumb.png "image_thumb[6]_thumb")
![image_thumb[16]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb16_thumb.png "image_thumb[16]_thumb")
![image_thumb[19]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb19_thumb.png "image_thumb[19]_thumb") \
\![image_thumb[21]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb21_thumb.png "image_thumb[21]_thumb")
![image_thumb[23]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb23_thumb.png "image_thumb[23]_thumb")
![image_thumb[28]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb28_thumb.png "image_thumb[28]_thumb")
![image_thumb[31]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb31_thumb.png "image_thumb[31]_thumb")
![image_thumb[33]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb33_thumb.png "image_thumb[33]_thumb")
![image_thumb[35]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb35_thumb.png "image_thumb[35]_thumb")
![image_thumb[38]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb38_thumb.png "image_thumb[38]_thumb")
![image_thumb[41]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb41_thumb.png "image_thumb[41]_thumb")
![image_thumb[43]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb43_thumb.png "image_thumb[43]_thumb")
![image_thumb[45]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb45_thumb.png "image_thumb[45]_thumb")
![image_thumb[47]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb47_thumb.png "image_thumb[47]_thumb")
![image_thumb[50]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb50_thumb.png "image_thumb[50]_thumb")
![image_thumb[52]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb52_thumb.png "image_thumb[52]_thumb")
![image_thumb[55]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb55_thumb.png "image_thumb[55]_thumb")
![image_thumb[57]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb57_thumb.png "image_thumb[57]_thumb")
![image_thumb[59]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb59_thumb.png "image_thumb[59]_thumb")
![image_thumb[64]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb64_thumb.png "image_thumb[64]_thumb")
![image_thumb[66]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb66_thumb.png "image_thumb[66]_thumb")
![image_thumb[68]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb68_thumb.png "image_thumb[68]_thumb")
![image_thumb[70]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb70_thumb.png "image_thumb[70]_thumb")
![image_thumb[72]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb72_thumb.png "image_thumb[72]_thumb")
![image_thumb[76]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb76_thumb.png "image_thumb[76]_thumb")
![image_thumb[78]_thumb](http://www.cleverworkarounds.com/wp-content/uploads/2018/06/image_thumb78_thumb.png "image_thumb[78]_thumb")